Micron ogłosił wysyłkę pierwszych próbek modułów SOCAMM2 o pojemności 256 GB, podnosząc poprzeczkę w segmencie pamięci niskomocowych dla serwerów AI i HPC. To nie jest wyłącznie kosmetyczny wzrost pojemności, ponieważ nowa konstrukcja ma bezpośrednio odpowiadać na dwa największe problemy współczesnej infrastruktury obliczeniowej, czyli rosnące zapotrzebowanie na pamięć oraz ograniczenia energetyczne platform serwerowych. Micron wykorzystuje przy tym monolityczną kość LPDDR5X 32 Gb, co pozwala zaoferować o jedną trzecią większą pojemność modułu względem poprzedniego pułapu 192 GB. W praktyce oznacza to możliwość budowy konfiguracji sięgających 2 TB LPDRAM na jednym ośmiokanałowym procesorze serwerowym, co może mieć znaczenie przy wnioskowaniu na dużych modelach językowych, pracy z rozbudowanym KV-cache oraz obciążeniach HPC o wysokiej intensywności pamięciowej.

Micron SOCAMM2 256 GB zwiększa pojemność pamięci dla AI i HPC
Najważniejszą cechą nowego modułu jest pojemność 256 GB, czyli o 33% wyższa niż w przypadku poprzedniego rekordzisty z segmentu SOCAMM2. Micron wskazuje, że taki skok otwiera drogę do uzyskania 2 TB pamięci LPDRAM na jednym ośmiokanałowym CPU. Dla platform AI oznacza to możliwość utrzymywania większych okien kontekstu bez konieczności agresywnego przerzucania danych do wolniejszych warstw pamięci masowej. Z kolei w środowiskach HPC rosnąca lokalna pojemność DRAM może ograniczyć zatory powstające przy analizie dużych zbiorów danych, modelowaniu numerycznym lub przyspieszeniu kodów naukowych zależnych od przepustowości i latencji pamięci.
Technicznie kluczowe znaczenie ma tu zastosowanie monolitycznej kości LPDDR5X 32 Gb. W praktyce pozwala to zwiększyć gęstość upakowania bez przechodzenia na bardziej złożone konfiguracje wieloukładowe. Taki kierunek jest istotny również z perspektywy termicznej i projektowej, ponieważ centra danych coraz mocniej szukają rozwiązań, które jednocześnie podnoszą pojemność pamięci i nie eskalują kosztów energetycznych całej platformy.

Micron SOCAMM2 256 GB ma ograniczać pobór mocy i powierzchnię na płycie
Micron podkreśla, że moduł SOCAMM2 ma zużywać jedną trzecią energii potrzebnej porównywalnym konfiguracjom opartym na klasycznych RDIMM, a przy tym zajmować jedną trzecią ich powierzchni na płycie. To bardzo ważny parametr dla serwerów nowej generacji, gdzie każdy wat i każdy milimetr przestrzeni przekładają się na gęstość upakowania, sprawność chłodzenia oraz finalny koszt utrzymania infrastruktury. W praktyce niskomocowe LPDRAM może stać się atrakcyjną alternatywą wszędzie tam, gdzie priorytetem nie jest wyłącznie maksymalna pojemność, ale także efektywność energetyczna całej platformy.
Istotne jest również to, że SOCAMM2 pozostaje modułem wymiennym, a nie pamięcią przylutowaną na stałe. Takie podejście poprawia serwisowalność, pozwala łatwiej skalować konfigurację i dobrze wpisuje się w projektowanie serwerów z chłodzeniem cieczą. W efekcie Micron nie proponuje tylko gęstszego nośnika pamięci, ale cały kierunek rozwoju modułowych, energooszczędnych platform dla obliczeń AI i HPC.
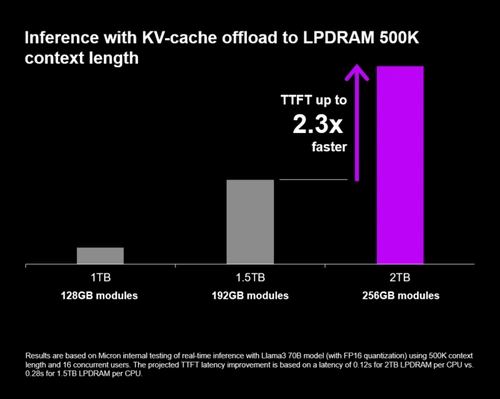
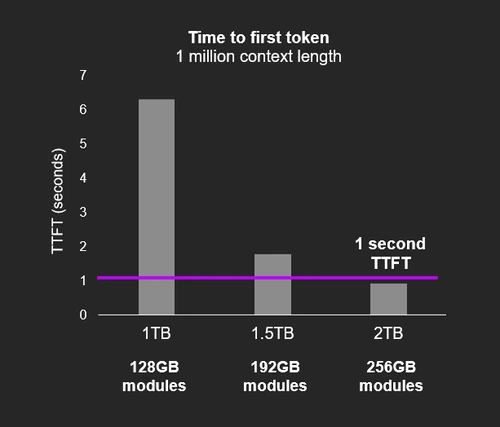
Micron SOCAMM2 256 GB przyspiesza wnioskowanie i obliczenia HPC
Micron deklaruje, że w scenariuszach długiego kontekstu dla LLM nowy moduł może poprawić czas do pierwszego tokenu o ponad 2,3 razy, jeśli jest wykorzystywany do offloadu KV-cache w architekturach pamięci zunifikowanej. Z punktu widzenia systemów AI to bardzo istotny parametr, ponieważ właśnie opóźnienie na początku odpowiedzi bywa jednym z elementów najbardziej odczuwalnych dla użytkownika końcowego oraz dla systemów agentowych wykonujących wiele sekwencyjnych operacji.
Firma dodaje także, że w samodzielnych zastosowaniach CPU pamięć LPDRAM ma oferować ponad trzykrotnie lepszą wydajność na wat w obciążeniach HPC. Oznacza to, że standard SOCAMM2 nie jest projektowany wyłącznie z myślą o modelach językowych, ale również o szeroko pojętych zadaniach obliczeniowych zależnych od przepustowości pamięci i kosztu energetycznego. Jeżeli te deklaracje potwierdzą się w gotowych platformach, SOCAMM2 może stać się jednym z ważniejszych elementów transformacji nowoczesnych serwerów obliczeniowych.
Micron SOCAMM2 256 GB zadebiutuje komercyjnie z platformą NVIDIA Vera Rubin
Wysyłka próbek do klientów oznacza, że standard wchodzi w fazę realnej walidacji po stronie partnerów. Micron wskazuje, że komercyjny debiut SOCAMM2 ma nastąpić wraz z platformą NVIDIA Vera Rubin w drugim kwartale 2026 roku. To właśnie ten moment pokaże, czy technologia przełoży się na szeroką adopcję poza demonstracjami i materiałami technicznymi. Dodatkowo zainteresowanie tym typem modułów mają wyrażać także AMD i Qualcomm, co sugeruje, że LPDRAM w formacie SOCAMM2 może wyjść poza pojedynczy ekosystem.
Z perspektywy rynku najważniejsze jest to, że producenci pamięci i projektanci platform zaczynają traktować niskomocowe LPDDR nie jako niszę dla urządzeń mobilnych, ale jako pełnoprawny komponent infrastruktury serwerowej. Micron, NVIDIA, Samsung i SK hynix rozwijają standard w ramach prac JEDEC, więc mówimy o ruchu, który może mieć długofalowe skutki dla projektowania serwerów AI, systemów HPC i pamięci przypiętej bezpośrednio do CPU.
Micron SOCAMM2 256 GB specyfikacja techniczna
| Parametr | Wartość |
| Standard modułu | SOCAMM2 |
| Pojemność modułu | 256 GB |
| Typ pamięci | LPDDR5X |
| Kość pamięci | monolityczna 32 Gb |
| Maksymalna konfiguracja | 2 TB LPDRAM na 8-kanałowy CPU |
| Pobór mocy | 1/3 energii porównywalnych RDIMM |
| Powierzchnia modułu | 1/3 powierzchni RDIMM |
| Przyrost TTFT | ponad 2,3x |
| Wydajność na wat | ponad 3x lepsza w HPC |
| Debiut komercyjny | II kwartał 2026 z NVIDIA Vera Rubin |
Podsumowanie
Micron SOCAMM2 256 GB to jedna z ciekawszych premier pamięci serwerowej ostatnich miesięcy, ponieważ nie skupia się wyłącznie na surowej pojemności. Nowy moduł łączy większą gęstość LPDDR5X z mocnym argumentem energetycznym i realnymi obietnicami poprawy wydajności w środowiskach AI i HPC. Jeżeli komercyjne wdrożenia faktycznie potwierdzą niższy pobór mocy, wzrost TTFT i sensowną skalowalność, standard SOCAMM2 może stać się ważnym elementem kolejnej generacji serwerów dla modeli językowych i obciążeń naukowo-obliczeniowych.